RK3588+FPGA+AI YOLO Fully Localized USV Object Detection System (Part 2): Platform Design

Based on project requirements, the overall architectural design of the domestic AI platform was determined, and the selection and setup of hardware units, along with the configuration of the development toolchain, were completed.
4.1 Overall Architecture of the Domestic AI Platform
This paper designs a flexible and efficient overall architecture for a domestic AI platform. The design method involves using a serial bus (Peripheral Component Interconnect Express, PCIe) or an RJ45 Ethernet port on an embedded platform to acquire 1080P image data streams. Then, through the collaborative work of relevant hardware units and software environments, it achieves forward inference of object detection algorithms and real-time display of detection results. Therefore, the processing flow architecture shown in Figure 4-1 was designed.

From the figure above, the main processing flow can be seen as:
(1) Complete algorithm development on the host PC and flash the program onto the computing and processing module.
(2) The video acquisition module obtains real-time detection footage via a camera. Data is transmitted to the computing and processing module via a PCIe interface through an FPGA-based image acquisition device, or directly transmitted to the video processing chip within the computing and processing module via a network camera.
(3) The CPU in the computing and processing module controls the encoding and decoding implementation of the video processing chip. Pixel values that meet the model format requirements are transmitted to the NPU for forward computation. The completed inference results are sent to the CPU for post-processing, and the image interface and corresponding functions are displayed on the GPU.
(4) Store the image detection results and output them in real-time on the result display module.
4.2 Hardware Solution for the Domestic AI Platform
After completing the overall architectural design of the domestic AI platform, the selection of the computing platform, acquisition card, and camera needs to be carried out. Selecting appropriate hardware devices can ensure localization, real-time detection, and performance stability.
Firstly, the selection of the computing and processing module needs to consider the platform's real-time detection requirements and performance demands. It is responsible for real-time object detection and analysis of acquired video data. Therefore, devices with stable performance and powerful computing capabilities must be selected to ensure the platform can respond in real-time and accurately identify targets.
Secondly, the performance of the acquisition card directly affects the transmission speed and stability of video data. Therefore, an appropriate acquisition card must be selected based on the platform's requirements to ensure it can meet the demands for high-speed data acquisition and stable transmission.
Finally, for camera selection, factors such as image quality, field of view, lighting conditions, and protection need to be considered. Choosing a suitable camera can ensure the platform receives high-quality video input, which is beneficial for subsequent object detection and analysis.
4.2.1 Domestic AI Chip Selection
Based on their position in the network, AI chips can be divided into three main categories: cloud, edge, and terminal [63]. Cloud AI chips are primarily used in data centers or cloud computing platforms for processing large-scale data and complex computational tasks. Edge AI chips perform real-time data processing and analysis close to the data source, typically featuring lower power consumption and smaller sizes, enabling them to execute deep learning inference tasks in resource-constrained environments. Terminal AI chips are specifically designed for IoT devices and embedded systems to enable local intelligent perception and decision-making, typically featuring extremely low power consumption and minimal sizes, allowing them to run lightweight deep learning models on devices with extremely limited resources.
Currently, applications tailored to specific scenarios have become the main driving force behind the development of the AI industry, leading domestic manufacturers to invest heavily in the R&D and production of AI chips. Table 4-1 introduces some representative domestic AI chips, and Figure 4-2 highlights a comparison of these chips in terms of power consumption and performance.
From Table 4-1 and Figure 4-2, it can be seen that after comprehensively considering power consumption and computing power, only HiSilicon Hi3559A V100 and Rockchip RK3588 can meet the project requirements. The former has limited AI framework support, while the latter has slightly higher power consumption. Apart from this, both are similar in terms of computing power, image processing capabilities, and other performance aspects, making both suitable as deployment platforms for object detection algorithms.

4.3 Software Solution for the Domestic AI Platform
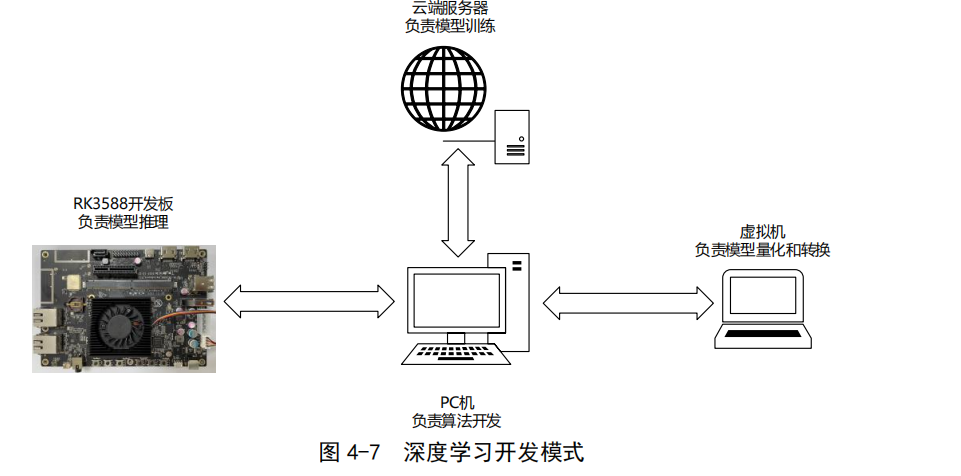
Due to the limited hardware resources of the RK3588, it is not feasible to perform the entire deep learning application process on the domestic AI platform. This paper combines various resources to subdivide the deep learning development process, forming the development model shown in Figure 4-7.