Unmanned Surface Vehicle Target Detection System Based on RK3588+FPGA+AI YOLO (Part 1) Overview
Unmanned surface vehicles (USVs) play a crucial role in fields such as marine monitoring, resource exploration, maritime security, and scientific research, improving the efficiency and safety of maritime operations. In this process, environmental perception technology and target detection technology complement each other, jointly forming the core functions of the system. With the rapid development of the artificial intelligence industry, various intelligent chips, sensors, processors, and embedded systems have been widely deployed, forming a relatively complete ecosystem. However, using foreign platforms for environmental perception poses information security issues, making the adoption of domestic platforms one of the key solutions to this problem. Therefore, this paper is dedicated to researching a surface target detection system based on domestic platforms and building a complete development toolchain. The main work is as follows:
(1) To address the issues of insufficient detection accuracy and speed of YOLOv5s and YOLOv8s on the RK3588 platform, we propose an improved method based on lightweight convolutions and attention mechanisms. This method enables accurate and fast detection while reducing the number of model parameters. By applying PAGCP and LAMP pruning algorithms to the improved YOLOv5s and YOLOv8s models, we achieved a reduction in both parameter count and floating-point operations, with mAP50 accuracy losses of only 0.045 and 0.057, respectively.
(2) To address the issue that most current target detection systems rely on foreign platforms, we designed a surface target detection system based on domestic platforms. The domestic RK3588 chip serves as the core computing platform, equipped with a high-performance NPU capable of performing neural network model inference within the chip, thereby accelerating deep learning tasks and improving system performance. To ensure efficient data acquisition and transmission, a data acquisition and transmission solution based on the domestic Logos2 FPGA was designed. It communicates with the RK3588 using a PCIe 3.0 interface, significantly enhancing data transfer speed and providing high-quality data support for subsequent target detection algorithms.
(3) To address the issue of low frame rates during deployment, the models were quantized using INT8 and INT16 methods, reducing the quantized size of the improved YOLOv5s model to only 26.25% of its original size, and the improved YOLOv8s model to only 16.51% of its original size. Additionally, multi-threading acceleration was applied to the inference process, successfully boosting the frame rate of the improved YOLOv8s model to 110 FPS. To address the issue of low NPU utilization, the CPU and GPU of the RK3588 were frequency-locked, fully leveraging the multi-core processing capabilities of the RK3588 and thereby improving NPU utilization.
With the rapid development of autonomous driving technology, unmanned aerial vehicles (UAVs) and autonomous vehicles have been widely applied in various scenarios in recent years. Meanwhile, Unmanned Surface Vehicles (USVs), as an emerging technology, are facing broad development prospects. In the past few years, USVs have been widely used in military and civilian fields, including but not limited to port security, vessel escort, maritime surveillance, water rescue, logistics supply, hydrological sampling, and marine environmental surveys. However, USVs face a severe challenge in environmental perception: how to achieve accurate docking and precise obstacle avoidance. The key to solving this problem lies in ensuring that USVs possess superior target detection capabilities [1], and achieving this goal requires suitable hardware platforms and target detection algorithms as support.
In the past 15 years, research on deep learning-based target detection algorithms has made significant progress, becoming a mainstream research direction [2-3]. Breakthroughs have been achieved in training and deployment on local GPUs and cloud servers, but both have certain limitations in practical applications. Local GPUs are large in size and have high power consumption, making them difficult to deploy on embedded platforms; the transmission speed of cloud servers is limited by network bandwidth, making it difficult to meet real-time requirements. In contrast, Artificial Intelligence (AI) chips are specifically optimized for visual and language computing features from the outset of their architectural design, facilitating the deployment of target detection algorithms. AI chips can simulate the functions of brain neurons and synapses, employing a computational model where a group of neurons processes a group of instructions, offering faster speed and lower power consumption for tasks such as image and audio processing.
In China, deep learning algorithm deployment platforms have always been a focal point in scientific research and industrial applications. Currently, commonly used platforms largely rely on foreign hardware and software technologies, such as Xilinx's ZYNQ [4] series and NVIDIA's Jetson [5-6] series. While these hardware platforms have achieved significant success in deep learning applications, they involve reliance on underlying inference frameworks, development environments, and ecosystems. Therefore, using domestic platforms can more effectively protect information security.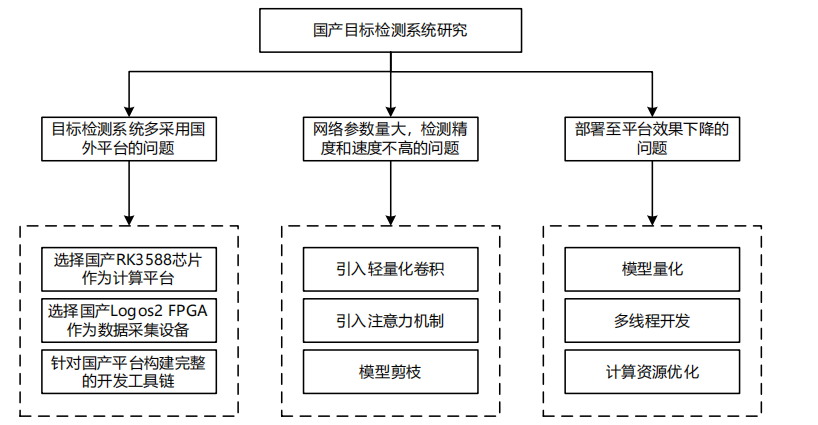
(1) Based on the requirements for domestic solutions, real-time acquisition, and fast inference, domestic hardware was appropriately selected. Specifically, the RK3588 is used for inference computation, and the Logos2 FPGA is responsible for data acquisition. The platform's overall average power consumption is only about 20W, enabling long endurance. Concurrently, a brand-new development toolchain was designed based on this platform.
(2) We propose a target detection algorithm based on improved YOLOv5s and YOLOv8s. By introducing lightweight convolutional structures into the original models, computational efficiency is enhanced, allowing for faster inference execution under limited hardware resources. These lightweight convolutional structures also occupy less storage space and memory, making them suitable for mobile devices, embedded systems, and edge devices. Furthermore, the issue of high power consumption caused by oversized models can also be mitigated by lightweight convolutional structures, making the improved models easier to deploy and maintain.
(3) A series of effective methods were adopted to improve the inference speed of the models on resource-constrained domestic AI platforms. Firstly, model quantization technology was used to reduce the computational complexity of the models by decreasing the number of model parameters, thereby increasing inference speed. While maintaining accuracy, the model size was successfully reduced, saving storage space. Secondly, thread pool technology was employed to parallelize the model inference tasks, fully utilizing the multi-core processors of the domestic AI platform and improving inference efficiency. Finally, hardware frequency locking was implemented. By adjusting the operating frequencies of the CPU and GPU, they can run at optimal performance under different loads, further enhancing inference speed and efficiency. These measures provide a feasible solution for efficient inference in resource-constrained environments.