Road Traffic Object Detection Design Based on ZYNQ MPSOC Heterogeneous Platform, also Supporting RK3588+FPGA
0
Introduction
In recent years, China's automotive industry has continuously upgraded and developed, with the sales proportion of new energy electric vehicles steadily increasing. Automobiles are gradually evolving towards technological and intelligent development. Autonomous driving technology and driving safety detection in smart cars are inseparable from object detection technology. Traditional object detection relies on manually designed and extracted features, resulting in low detection accuracy. With the rise of deep learning technology and convolutional neural networks, deep learning algorithms have replaced traditional algorithms, becoming the mainstream algorithms for current object detection tasks.
Conventional deep learning algorithms are typically deployed on high-performance computers, which are large in size and high in power consumption, making them inconvenient for installation in vehicles. Deploying object detection algorithms on embedded edge devices can effectively solve these problems. Edge devices have lower power consumption and smaller size, allowing for flexible installation and deployment. Current deep learning edge deployments primarily use ASIC platforms, but ASICs are customized platforms, usually targeting only a single model. Furthermore, they require significant time and capital from design and verification to the tape-out stage. Once designed, modifications are difficult, and it's challenging to ensure timely adaptation to rapidly evolving neural network models. In contrast, FPGAs, with their reconfigurable hardware structure and low power consumption characteristics, can be flexibly designed and modified, better adapting to the upgrading, adjustment, and deployment of network models.
Regarding the deployment of neural network models on FPGAs, Chen Chen et al. designed a single-instruction, multiple-data (SIMD) convolutional neural network accelerator architecture based on FPGA. They deployed the YOLOv2 network using high-level synthesis methods, conducting in-depth analysis and modeling of the accelerator's performance and resource consumption. However, the code generated by high-level synthesis has poor readability, making further optimization difficult. Chen Haomin et al. proposed a YOLOv3-tiny based network model accelerator. By lightweighting the network model, it met the deployment requirements in the embedded field. However, the accuracy of the lightweighted network was lower. Wu Shixiong et al. proposed a convolutional neural network accelerator based on parameter quantization. This accelerator performed 8-bit fixed-point quantization and reordering of parameters, effectively reducing memory footprint and access times, and improving bandwidth utilization. At the same time, this research adopted an inter-sliding window parallel strategy for acceleration, increasing image classification speed.
The above solutions all deployed neural networks on FPGAs. However, these accelerators all required single design optimization on hardware for a single network, resulting in low flexibility. For non-professional hardware developers, the development difficulty is high and the cycle is long, making it difficult to adapt to rapidly iterating neural network model deployments. Therefore, there is a need for a neural network model acceleration method that is highly universal, supports basic network model operators, has a short development cycle, and a concise development process.
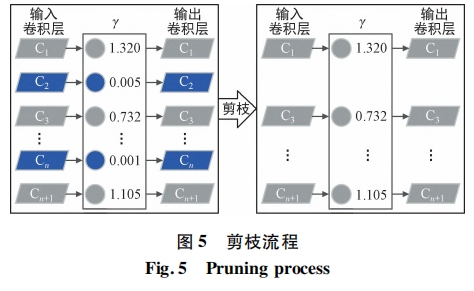
To address the above issues, this paper proposes a road traffic object detection solution based on an FPGA+ARM heterogeneous platform. By adding network detection layers, an improved YOLOv3-4L network is obtained to enhance model detection accuracy. By reducing network parameters and computation through pruning, quantization, and other methods, a YOLOv3-4L-prune network is obtained to improve detection speed. At the underlying hardware level, a Deep Learning Processing Unit (DPU) is used as the core to build a hardware platform for parallel acceleration of convolutional operations. During deployment, the network is deployed through Xilinx's Vitis AI platform by performing network quantization, compilation, and generating executable files. This achieves road traffic object detection design on an embedded platform.
1 Object Detection Algorithm Optimization
YOLOv3 is a widely used object detection algorithm. It detects the type and specific location of target objects through regression. It boasts high detection accuracy and a moderate model size, making it suitable for deployment on edge devices. During the original algorithm's feature scale detection, some tiny vehicle targets and overlapping vehicle targets might be missed. The improved YOLOv3-4L network structure is shown in Figure. This paper modifies the original algorithm structure.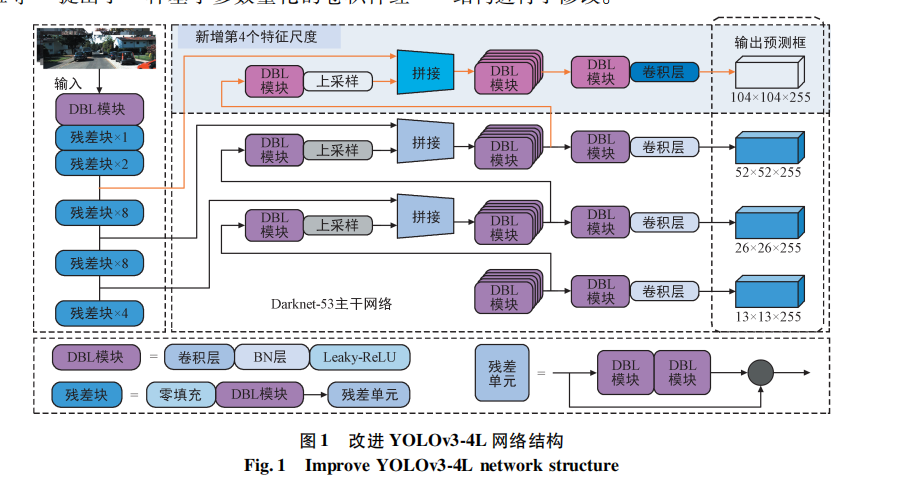
The original backbone network of YOLOv3 is Darknet-53. This paper adds a fourth feature scale (104×104) based on the algorithm's original 3 feature layers. By performing 2x upsampling on it, the output feature scale is increased from 52×52 to 104×104. Concurrently, a route layer is used to merge the 109th layer with the 11th layer feature of the feature extraction network. This fully utilizes deep and shallow features to better recognize tiny and overlapping vehicle targets. Additionally, other feature fusion operations were performed: The 85th and 97th network layers, output via 2x upsampling, are fused. A route layer is used to fuse the feature maps of the 85th layer with the 61st layer, and the 97th layer with the 36th layer. The four improved feature scales are: 104×104, 52×52, 26×26, and 13×13, respectively. Increasing the model's feature scales enables the fusion of multi-scale information, mitigates feature loss, enhances semantic richness, strengthens the network's global perception capabilities, and improves issues of missed and false detections for vehicles.
2 Overall Deployment Design
2.1 Hardware Platform Design
The hardware platform in this paper is designed with the DPU as its core, combined with instantiated ZYNQ Ultrascale+MPSoC IP cores, clock modules, reset modules, and other components. The DPU is a parameterizable computing engine introduced by Xilinx. It can perform inference for convolutional neural network models and deep neural network models [14]. Its hardware structure is shown in Figure 2. It is equivalent to a set of parameterizable IP cores, deployed on the FPGA side of a heterogeneous platform. The DPU has a dedicated instruction set that supports common neural network operators such as convolution, depthwise convolution, max pooling, and fully connected layers.