Domestic Alternative to NVIDIA Jetson Nano: Sophon BM1684X + FPGA + AI Compute Box, Supporting DeepSeek Edge Deployment
A domestic alternative to the NVIDIA Jetson Nano, an AI compute box based on Sophon BM1684X, supporting DeepSeek edge deployment.
Additionally, a BM1684X + FPGA + AI solution is also available.

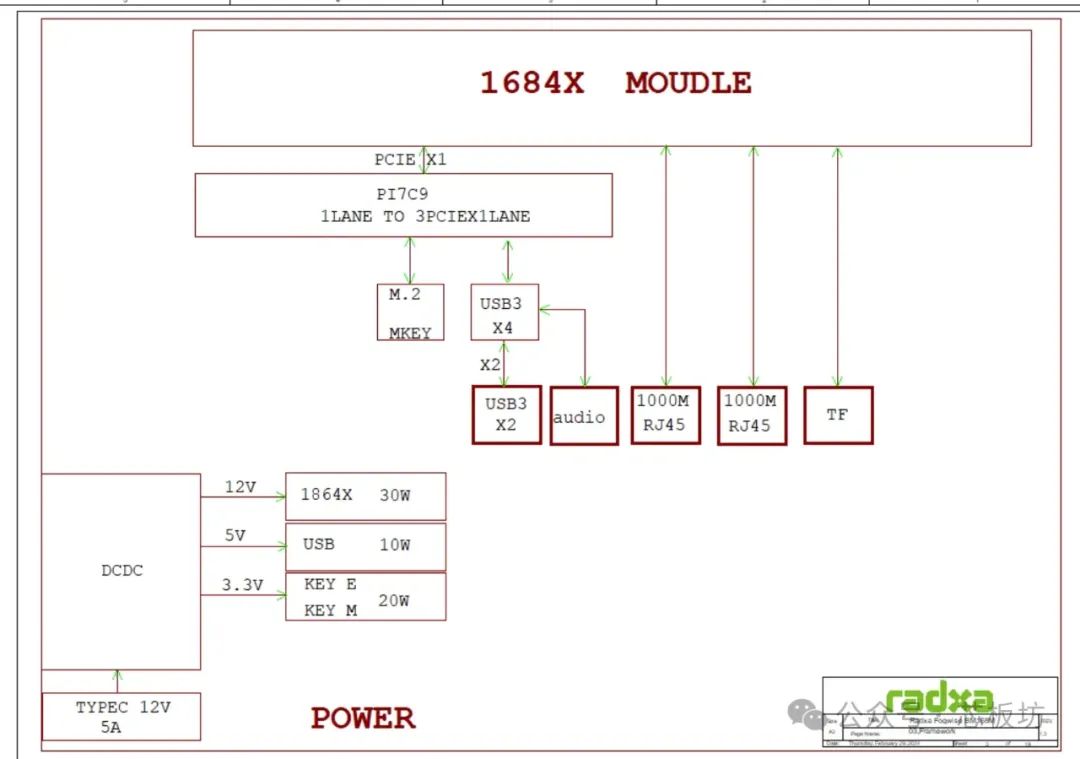
The core board is built upon the Sophon SG2300X SoC (also known as BM1684X).

It features an 8-core ARM Cortex-A53 @2.3GHz, with a very high clock speed.
Equipped with a TPU (Tensor Processing Unit).
Compute power reaches 32TOPS@INT8, 16TFLOPS (FP16/BF16), and 2TFLOPS (FP32).
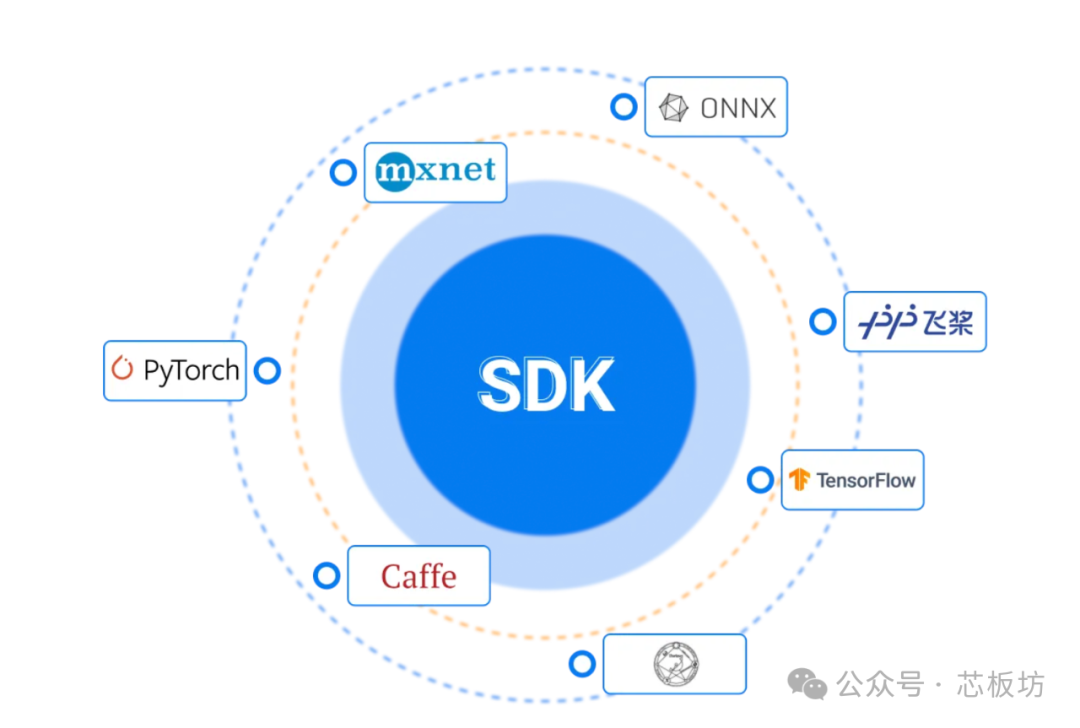
Supports deep learning frameworks such as TensorFlow, Caffe, PyTorch, Paddle, ONNX, MXNet, Tengine, and DarkNet.
The Video Processing Unit (VPU) supports 32-channel H.265/H.264 1080P@25fps decoding and 12-channel encoding.

JPEG encoding/decoding supports 1080P@600fps, with a maximum resolution of 32768×32768. Post-processing functions include image scaling, cropping, and color space conversion.
Paired with 16GB LPDDR4X memory. Looking at the chip block diagram, it appears to be four 4GB memory chips, potentially quad-channel, which would suggest good speed.
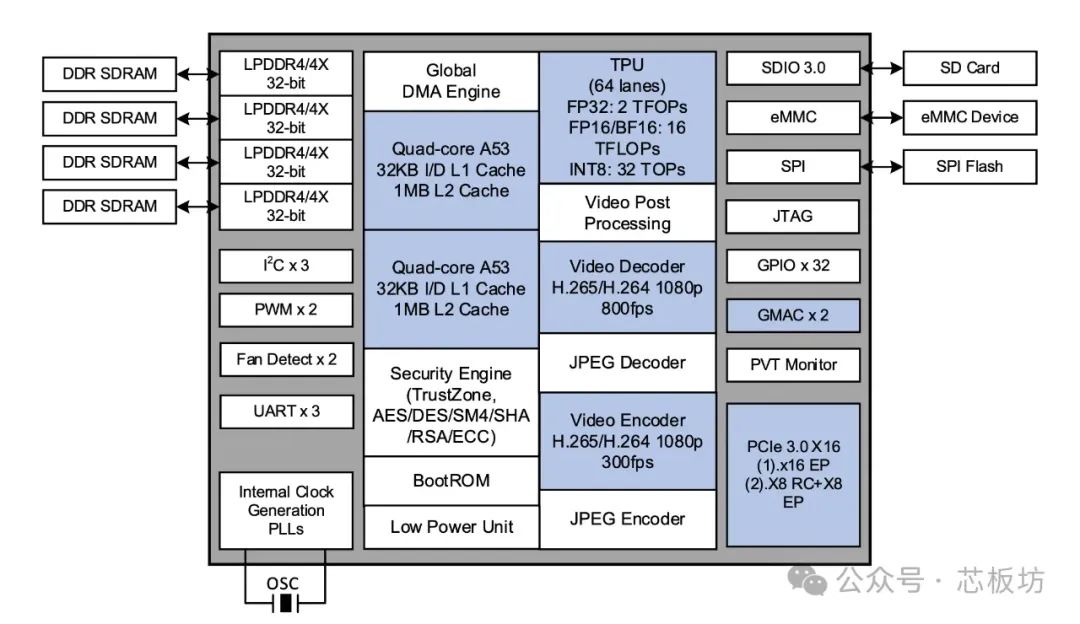
64GB eMMC 5.1, 16MB SPI Flash.
The core board is mounted onto the expansion board via a 144-pin board-to-board connector, exposing numerous interfaces. The expansion board features M.2 E Key (for Wi-Fi/BT modules) and M.2 2230 NVMe SSD. Externally, there are two USB 3.0 Host ports and two Gigabit Ethernet ports.

One USB Type-C power interface supports PD (Power Delivery), with 20V input support, specifically 20V 3.25A or higher, meaning it supports power supplies of 65W or more.
One USB Type-C Debug UART interface, and a MicroSD card slot.
Operating temperature: 0~40℃.
Dimensions: 104×84×52mm.
Regarding the system, the official team provides two images: one is a base image, based on Ubuntu Server 20.04, containing only the Sophon base SDK and backend, and is only 1.2GB in size.
The other is a full image, also based on Ubuntu Server 20.04, including the Sophon SDK and backend, pre-installed with the Radxa LLM frontend, pre-installed with CasaOS, and common LLM demos, with a size of 9.5GB.
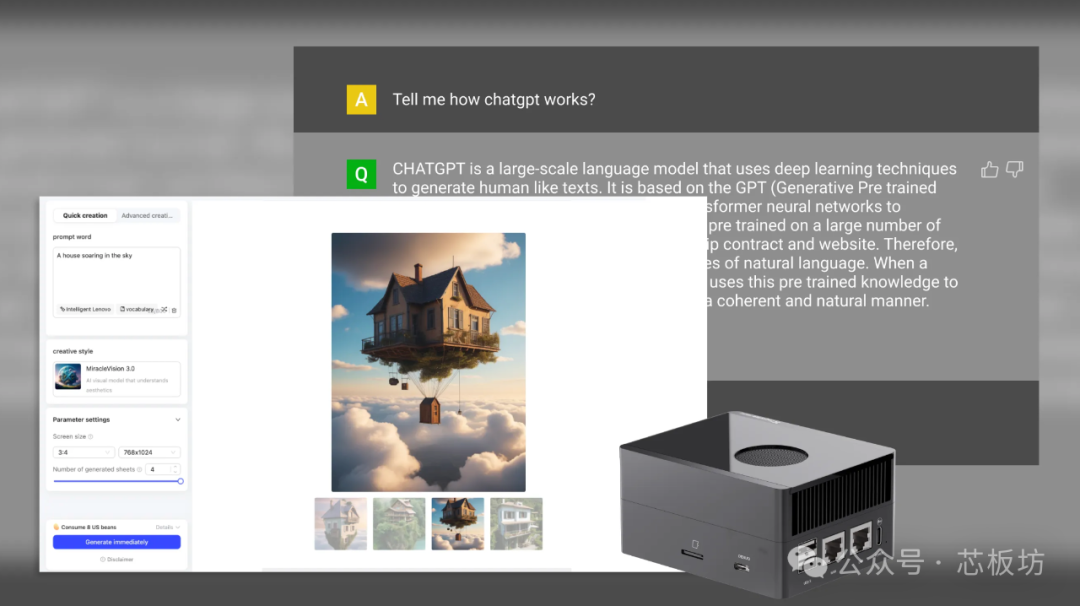
The highlight of this AirBox lies in its pre-installation of CasaOS, which greatly simplifies the barrier to deploying large models, making deploying various large models extremely easy.
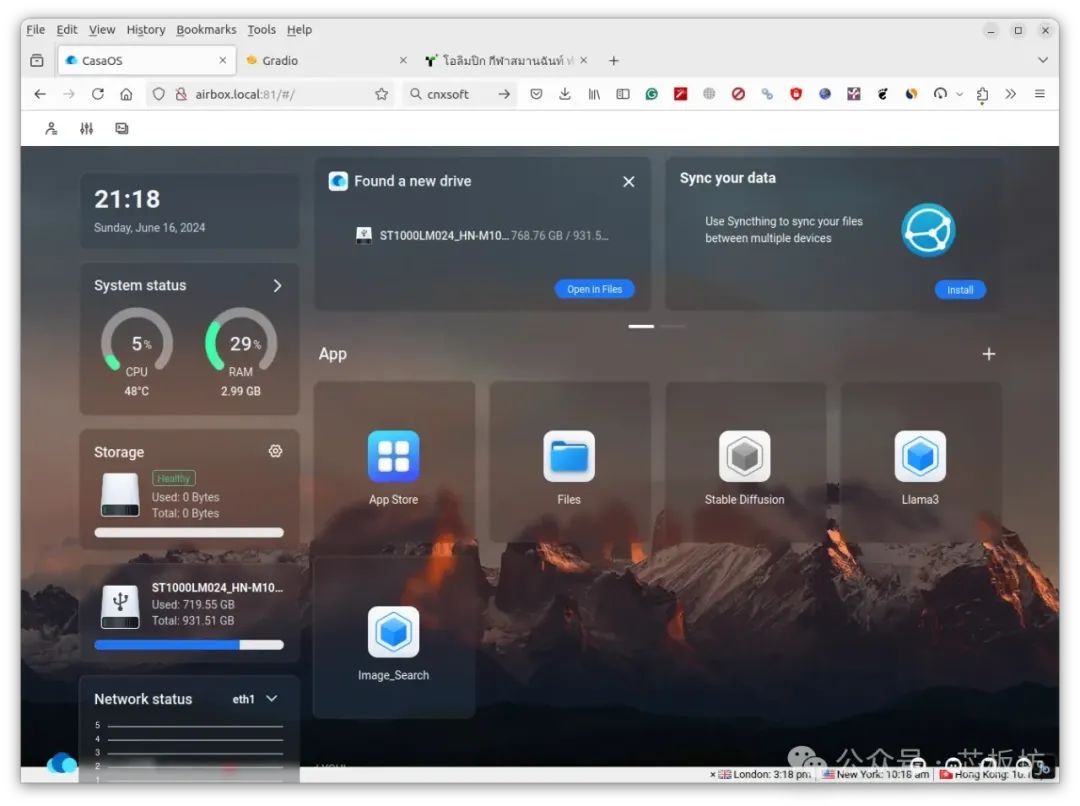
The official full image defaults to pre-installing Stable Diffusion.
Deploying Whisper, ChatGLM2, ChatDoc, Chatbot, ImageSearch, and Llama3 is also very easy, requiring just a few simple steps to complete the deployment, making these tasks pleasant and easy on Linux.
You can also package your own Docker images; the official team provides tutorials for reference, which will make subsequent deployments quite simple.
The main highlight is actually the local deployment of LLM (Large Language Models), capable of deploying:
ChatGLM2, ChatDoc, Chatbot
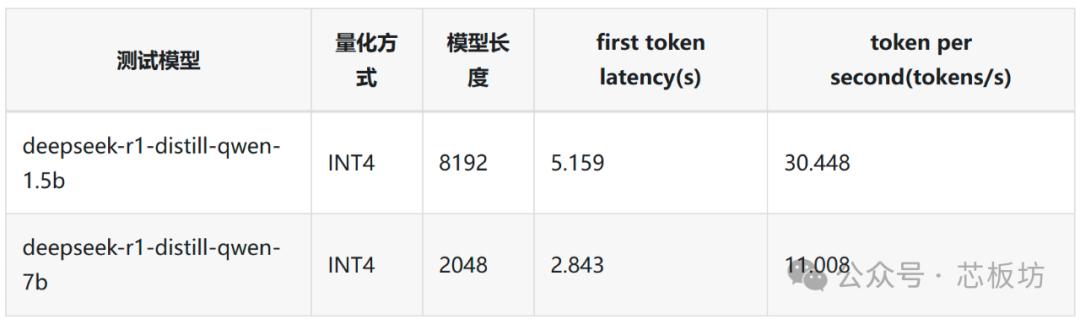
Llama3, Qwen2, DeepSeek R1 The official team introduced the deployment of two Qwen2.5 distilled models: deepseek-r1-distill-qwen-1.5b and deepseek-r1-distill-qwen-7b.
Both use INT4 quantization. Currently, the 1.5B model achieves an inference speed of up to 30.448 tokens/s on the AirBox, while the 7B model achieves an inference speed of up to 11.008 tokens/s.
The Llama3 8B model achieves an inference speed of up to 9.566 tokens/s.
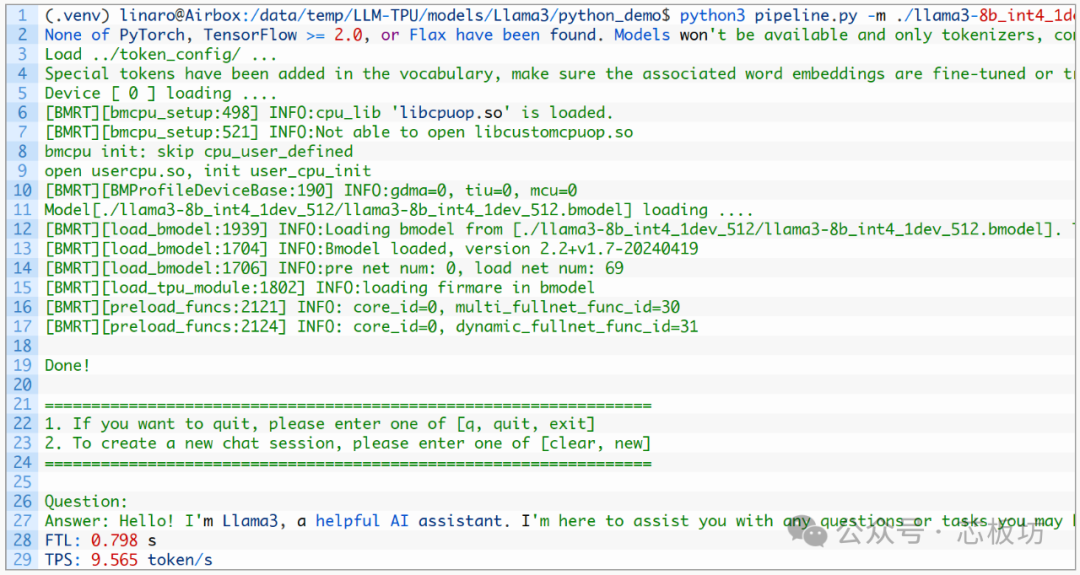
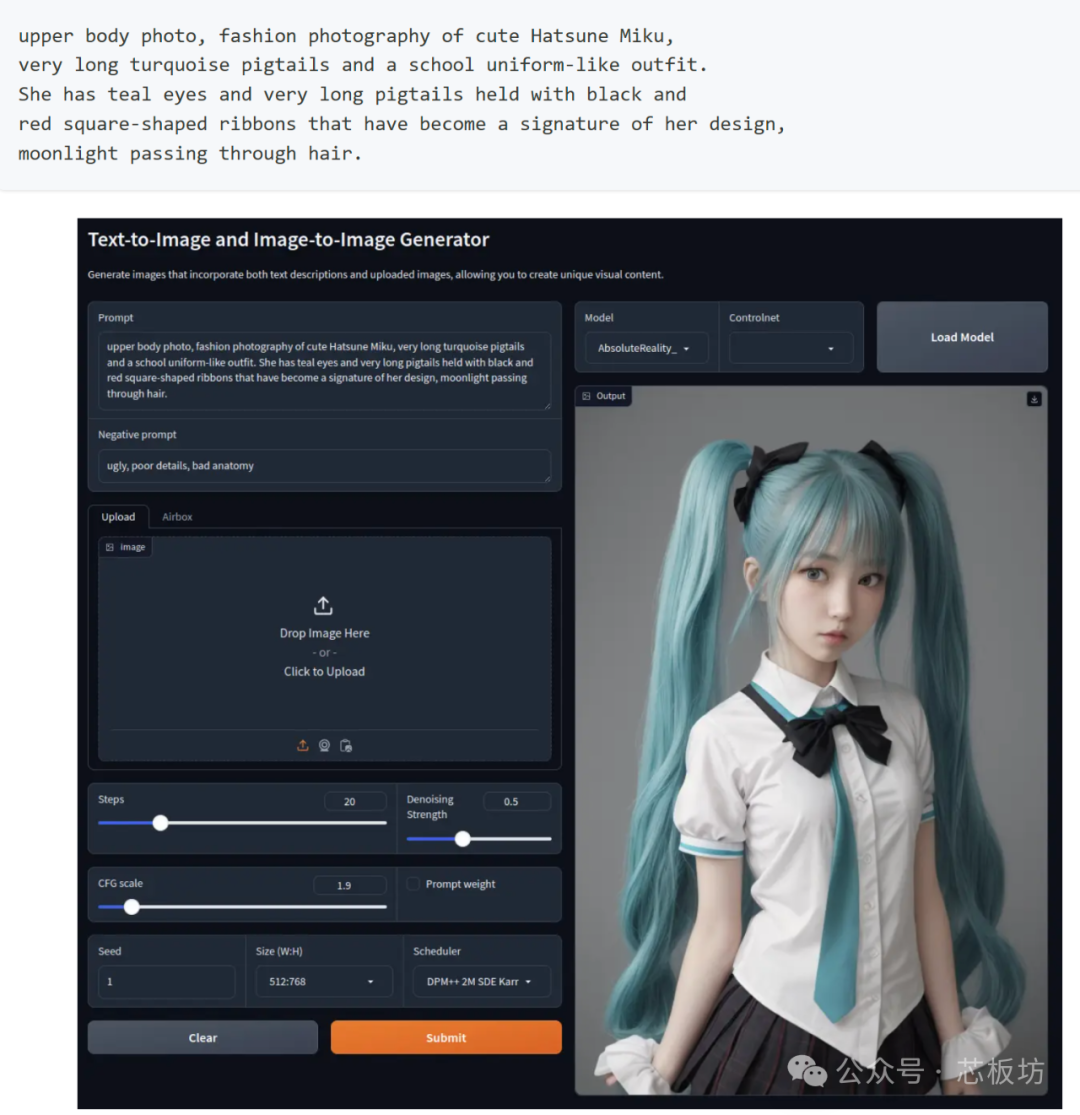
Text-to-image large models support the deployment of Stable Diffusion 1.5, Real ESRGAN, Stable Diffusion 3 Medium, and FLUX.1, all of which can run normally. Generating a 512x512 image with Stable Diffusion 1.5 takes approximately 7 seconds.
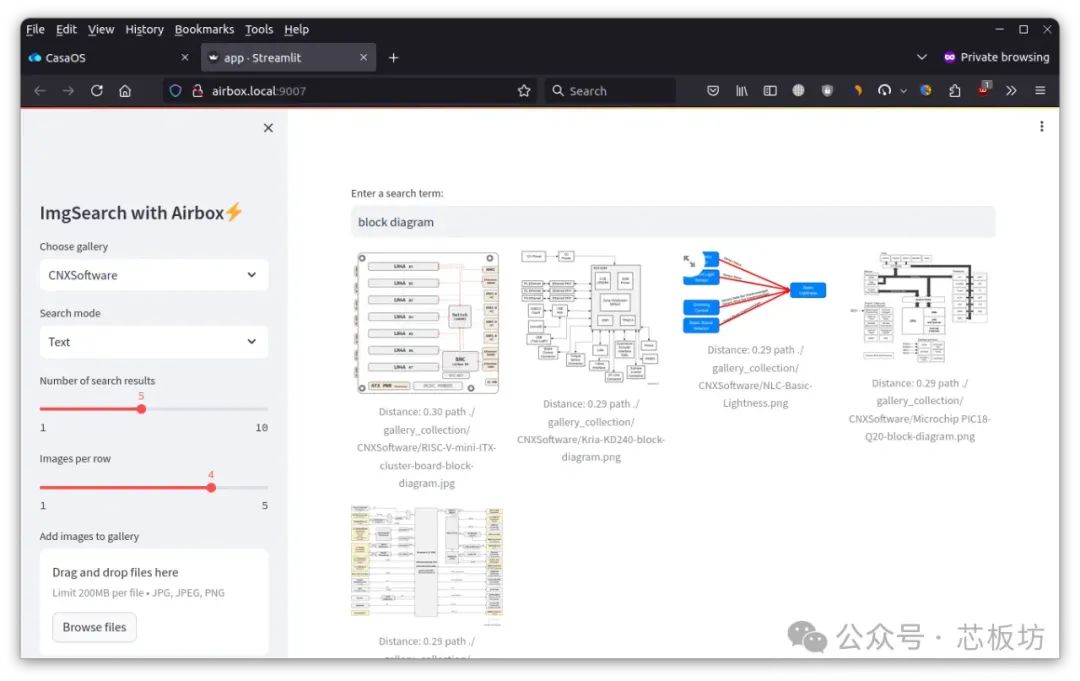
In addition, it also supports Image Search (text-to-image search) and Video Search (text-to-video search), as well as vector search model applications.
It supports the deployment of TTS/STT models like Emoti Voice and Whisper. It also features the MiniCPM-V2.6 visual multimodal model.
For more models, Radxa has also prepared a Model-Zoo, where various algorithm applications such as object detection, semantic segmentation, and facial detection can be deployed.
Radxa also provides the TPU-MLIR compiler toolchain, used to convert pre-trained neural network models from various frameworks into bmodel format models that can run on Sophon TPUs.
It directly supports PyTorch, ONNX, Caffe, and TFLite. Models from other frameworks need to be converted to ONNX.
After conversion, Radxa also provides TPU-PERF for TPU loading/inference of bmodel models converted by TPU-MLIR.