PCIe Topology for AI Servers Based on Domestic PCIe 4.0/5.0 Switches and Application Research of PCIe 5.0 Retimer Cards (Part 3)
HPL Performance Analysis
HPL (High-Performance Linpack) tests can characterize the performance of the three topologies in double-precision floating-point operations. The HPL performance test results for the three topologies—BalanceMode, CommonMode, and CascadeMode—are shown in Table 3.

To clearly characterize the performance differences of the three topologies in HPL performance tests, taking BalanceMode's test score as the baseline, the proportion of HPL performance test scores for Common Mode and Cascade Mode relative to BalanceMode's score is obtained, as shown in Figure 6.

HPL tests require the use of processors and main memory. Due to the increased uplink bandwidth and memory utilization of dual-root topologies, performance will be superior to single-root topologies. Therefore, BalanceMode and CommonMode will achieve higher scores in HPL tests than CascadeMode. Furthermore, in the BalanceMode architecture, 8 GPUs are evenly distributed across two CPUs, allowing the utilization of resources from both CPUs and their memory to complete floating-point operations. In CommonMode, although all GPUs are connected to CPU0, because the UPI connection speed between CPUs is as high as 10.4 GT/s, when 8 GPUs perform floating-point operations simultaneously, they can communicate with CPU1 via UPI and share memory. Therefore, overall, BalanceMode's HPL performance will be slightly higher than CommonMode's.
3.2.3 Deep Learning Performance Analysis
Deep Learning (DL) processes and recognizes images, videos, and audio using computational models composed of multiple processing layers [6]. Common models include autoencoders, restricted Boltzmann machines, deep neural networks, convolutional neural networks, and recurrent neural networks. Among these, convolutional neural networks [7] are widely used in image processing, as shown in Figure 7.
Figure7 Imageprocessingusingconvolutionalneuralnetwork Figure 7 Image processing using convolutional neural networks
At the 2017 GPU Technology Conference (GTC), NVIDIA released the Volta-based V100 GPU. The V100 GPU was the first NVIDIA GPU to include "Tensor Cores," which are cores designed for 4x4 matrix multiplication operations and are a key component of deep learning models [8].
Deep learning training models primarily use two distribution strategies—data parallelism and model parallelism [9]. This experiment adopts a data-parallel strategy. For data parallelism, each GPU has a complete copy of the deep learning model. Each GPU receives different parts of the data for training, and then its parameters are updated to all GPUs via RingAll-Reduce, so that all GPUs share their training output. As shown in Figure 8, taking BalanceMode as an example, when running data-parallel deep learning training models, if multiple machines are used, GPU communication flows are transmitted between machines via IB (InfiniBand) cards. When a single machine is running, based on the NCCL (NVIDIA Collective Communications Library) communication library, the information transfer among 8 GPU cards forms a ring communication flow. Compared to the communication bandwidth between GPUs, reduced communication bandwidth between the CPU and GPU will affect the time required for the GPU to obtain the dataset, i.e., the time required to complete one batch size.
Figure8 Dataparallelcommunication modeforBalancemode Figure 8 Data parallel communication mode for BalanceMode
There are many types of deep learning training models, and different models have different advantages and can be applied to various real-world scenarios. As shown in Figure 9, the ResNet computational model draws inspiration from the Highway Network concept, built using residual networks, with an optimization goal for output and input...

At the 2017 GPU Technology Conference (GTC), NVIDIA released the Volta-based V100 GPU. The V100 GPU was the first NVIDIA GPU to include "Tensor Cores," which are cores designed for 4x4 matrix multiplication operations and are a key component of deep learning models [8].
Deep learning training models primarily use two distribution strategies—data parallelism and model parallelism [9]. This experiment adopts a data-parallel strategy. For data parallelism, each GPU has a complete copy of the deep learning model. Each GPU receives different parts of the data for training, and then its parameters are updated to all GPUs via RingAll-Reduce, so that all GPUs share their training output. As shown in Figure 8, taking BalanceMode as an example, when running data-parallel deep learning training models, if multiple machines are used, GPU communication flows are transmitted between machines via IB (InfiniBand) cards. When a single machine is running, based on the NCCL (NVIDIA Collective Communications Library) communication library, the information transfer among 8 GPU cards forms a ring communication flow. Compared to the communication bandwidth between GPUs, reduced communication bandwidth between the CPU and GPU will affect the time required for the GPU to obtain the dataset, i.e., the time required to complete one batch size.
=================PCIe5.0 Retimer Card==============
- Eliminates deterministic and random jitter
- Tx/Rx per-channel performance adjustable
- 2*MICROx8 interfaces
- Supports hot-plugging
- Low power consumption, low latency
- Complies with PCIe 5.0 base specification.

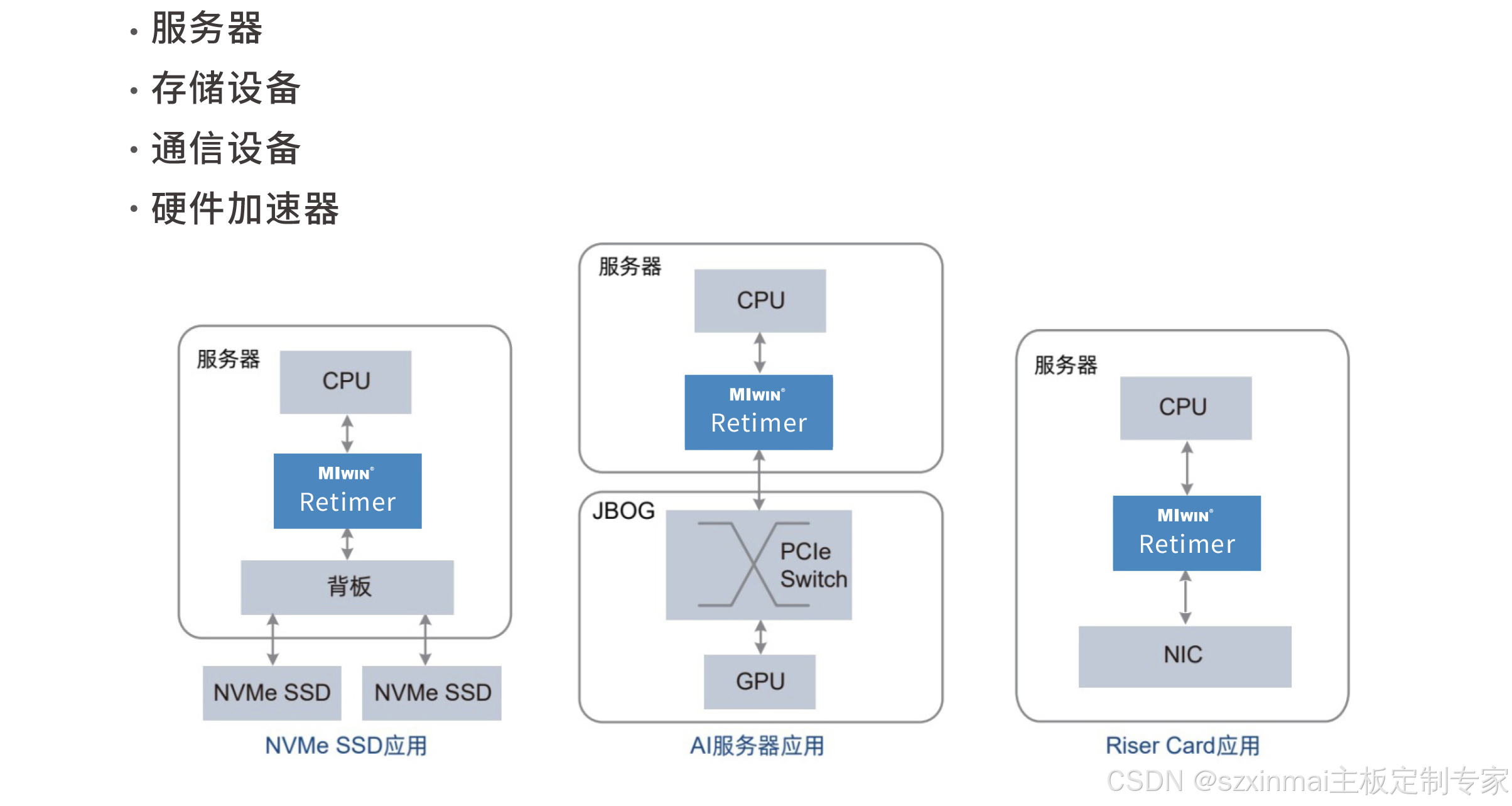
Features
· High-performance 32GT/s SerDes; · 2*MICROx8 interfaces; · Tx/Rx per-channel performance adjustable; · Supports channel polarity inversion; · Supports hot-plugging; · Low power consumption, low latency; · Complies with PCIe 5.0 base specification;
☑ Supports OEM/ODM customization services