PCIe Topology for AI Servers Based on Domestic PCIe 4.0/5.0 Switches and Application Research of 12Gb SAS Expander Multi-bay Backplanes (Part 2)
2.2 Topology Characteristics Analysis
The BalanceMode configuration evenly distributes GPUs across 2 CPUs, resulting in higher total upstream PCIe bandwidth for the GPUs. CommonMode can, to some extent, satisfy point-to-point communication between GPUs while ensuring sufficient I/O bandwidth between CPUs and GPUs. CascadeMode has only one ×16 link, but because GPUs are daisy-chained through PCIe Switches, it improves point-to-point performance and reduces latency.
For double-precision floating-point operations, GPU computation requires the use of processors and main memory. Due to the increased upstream bandwidth and memory utilization of the Dualroot topology, its performance will be superior to that of the Singleroot topology.
For deep learning inference performance, GPUs with parallel computing capabilities can perform billions of computations based on trained networks, thereby quickly identifying known patterns or targets. The interconnection relationships between GPUs differ across various topologies, and communication between GPUs affects the overall performance of deep learning inference.
3 Experiments and Results Analysis
3.1 Experimental Setup
To investigate the performance differences of the three topologies under various application conditions, the experiment used a self-developed AI server (NF5468M5) as the test platform. The setup used 2 CPUs, specifically IntelⓇ XeonⓇ Gold 6142, with a base frequency of 2.60GHz. It used 12 DDR4 memory modules, each with a capacity of 32GB, operating at 2666 MHz. It used 8 GPUs, specifically NVIDIA Tesla-V100_32G.
3.2 Experimental Results Analysis
3.2.1 Point-to-Point Bandwidth and Latency
GPU P2P performance can be measured by bandwidth and latency. PCIe 3.0 bandwidth is 16GB/s. Ideally, in practical applications, bandwidth can reach about 80% of the theoretical bandwidth. PCIe latency primarily depends on the length of the PCIe trace, devices along the routing path, whether it passes through UPI, whether it crosses an RC (Root Complex), etc.
As shown in Figure 4, point-to-point bandwidth and latency were tested for GPUs connected under the same PCIe Switch (line ① in Figure 4) and GPUs across PCIe Switches (line ② in Figure 4) in the BalanceMode, CascadeMode, and CommonMode topologies. The test results are shown in Table 1, Table 2, and Figure 5.
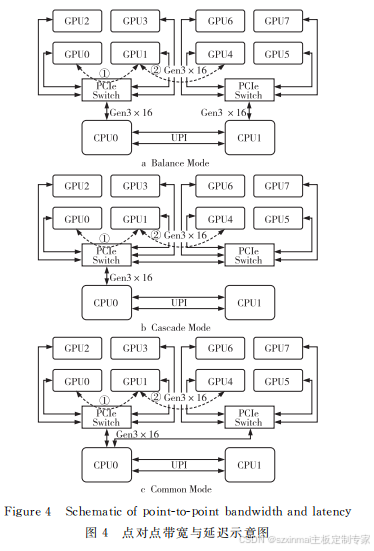
Under the same PCIe Switch, since the transmission distance between GPUs is the same, the bandwidth and latency results for all three topologies are similar in point-to-point path ①. For two GPUs across PCIe Switches, because there are 3 UPI Links between CPUs, the signal transmission speed is sufficiently fast, so the results for BalanceMode and CommonMode are similar.
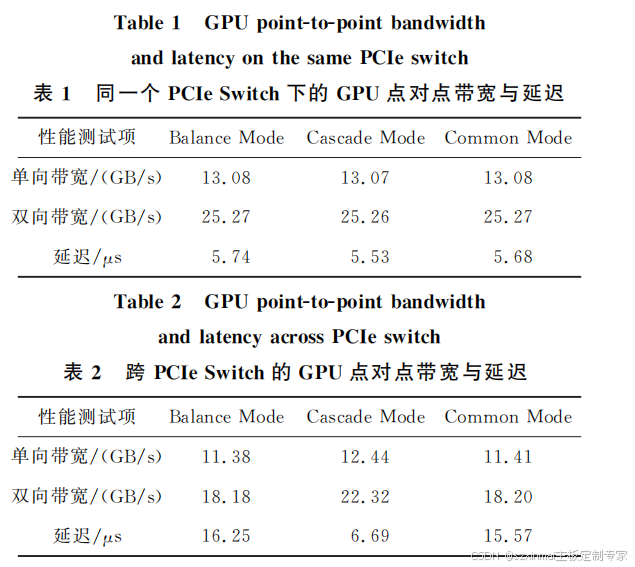
However, for CascadeMode, since communication between GPUs only needs to pass through a PCIe Switch, the transmission path is shortened, leading to improved point-to-point latency performance. Additionally, for Intel CPUs, a PCIe ×16 Port constitutes one RC. Communication bandwidth between different RCs is worse than communication between PCIe Switches under the same RC. Therefore, CascadeMode's bandwidth is also improved.
=========12Gb SAS Expander Multi-bay Backplane================ *Hard drive hot-swap functionality; *LED indicators support drive power-on, read/write activity, and error status; *SPGIO drive error reporting function; *Timed drive spin-up; *Fan temperature control; *I2C (BMC);

