Easily Harnessing AI with FPGAs
Launching artificial intelligence applications has never been easier! Thanks to FPGAs like the Xilinx Zynq UltraScale+ MPSoC, AI can now also be used offline or deployed and utilized at the edge. They can be used to develop and deploy machine learning applications for real-time inference, making AI integration into applications a breeze. Image detection or classification, pattern or speech recognition are driving upgrades in industries such as manufacturing, healthcare, automotive, and financial services.
Rapidly Enabling AI-based FPGA Applications
Artificial intelligence is occupying an increasing number of application and life scenarios, such as image detection and classification, translation, and recommendation systems. The number of applications based on machine learning technology is vast and continues to grow. By using core board modules from Realsun that combine FPGAs and ARM processors, using AI offline and at the edge has become easier than ever before.
Artificial Intelligence (AI) has a long history, recognized as a discipline since 1955. AI is the ability of computers to mimic human intelligence, learn from experience, adapt to new information, and perform human-like activities. Applications of AI include expert systems, Natural Language Processing (NLP), speech recognition, and machine vision.
The Resurgence of AI
After several waves of optimism and disappointment, there is renewed and growing interest in artificial intelligence. Over the past 15 years or so, thousands of AI startups have been founded, and the pace continues to accelerate. There are several driving factors behind this: Perhaps the most significant is the availability of immense computing power at an affordable price. Not only is hardware faster, but everyone now has access to supercomputers in the cloud. This has democratized the hardware platforms required to run AI, allowing a proliferation of startups.
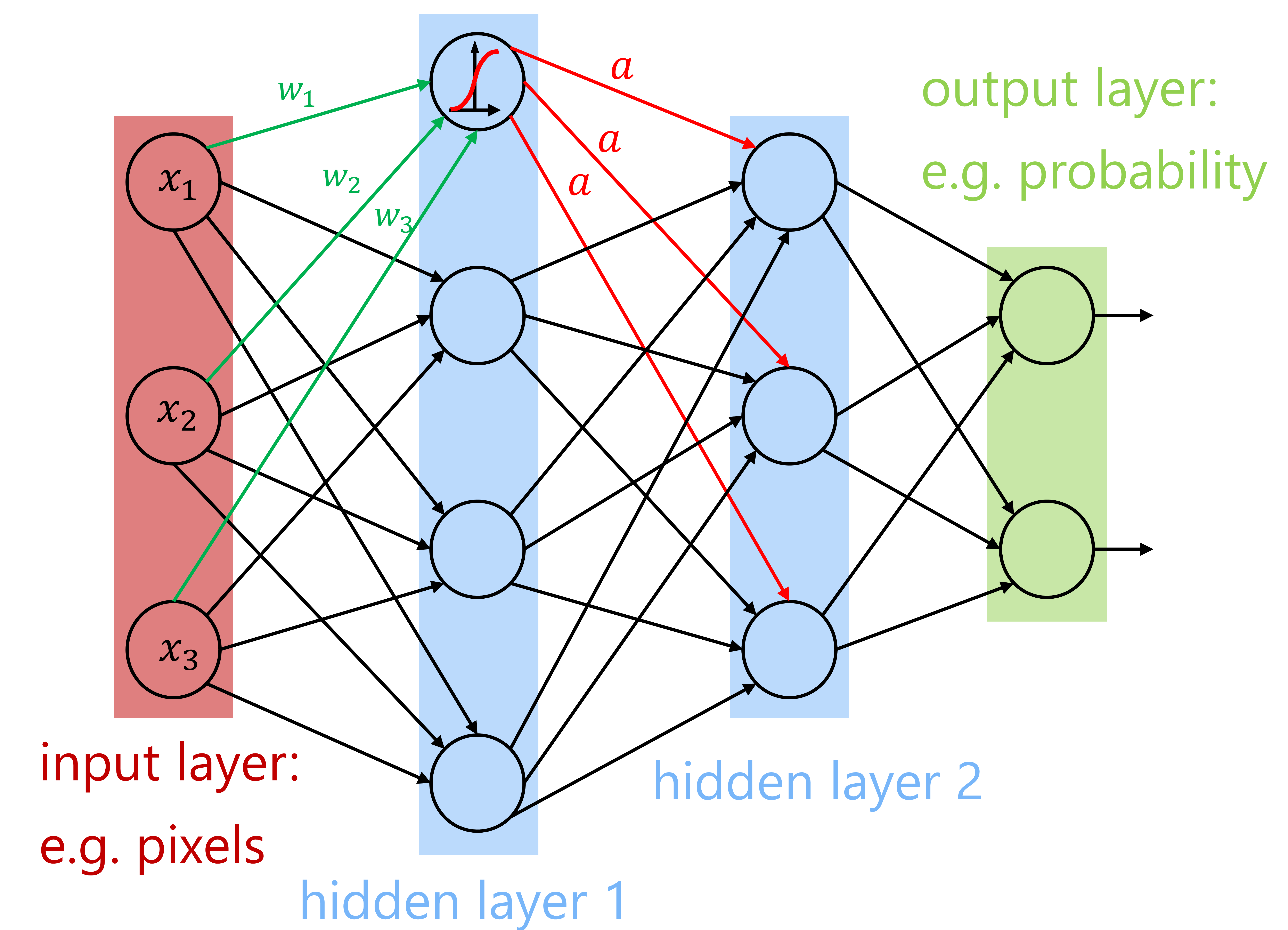
Figure 1: A simplified view of a feedforward artificial neural network with two hidden layers
Artificial neural networks (Figure 1) now extend to tens or hundreds of hidden layer nodes (Figure 2). Networks with even 10,000 hidden layers have been realized. This evolution is increasing the abstraction capabilities of neural networks and enabling new applications. Today, neural networks can be trained on tens of thousands of CPU or GPU cores, significantly accelerating the process of developing generalized learning models.
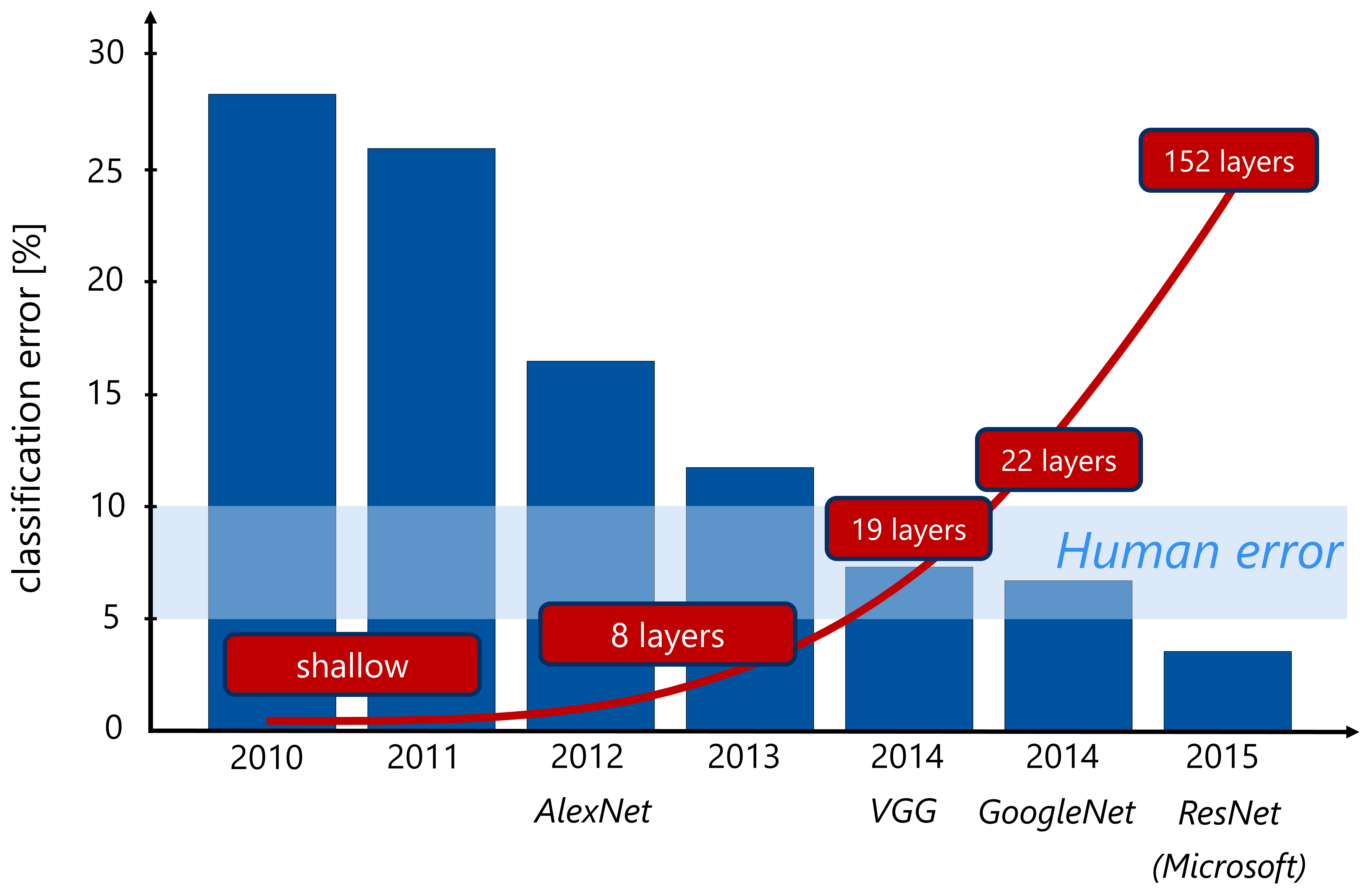
Figure 2: ImageNet Recognition Challenge winners demonstrate the increasing number of hidden layers in new neural network architectures
Another reason for the increased interest in AI is the breakthrough advancements in machine learning in recent years. This has helped attract technology investment and startup interest, further accelerating the development and refinement of AI.
How Machines Learn
Artificial neural networks are computational models inspired by the human brain. They consist of a network of simple processing units interconnected, which can learn from experience by modifying their connections (Figure 1). So-called Deep Neural Networks (DNNs – neural networks with many hidden layers) currently provide the best solutions for many large-scale computational problems.
Currently, the most widely applied deep learning systems are Convolutional Neural Networks (CNNs). These systems use feedforward artificial neural networks to map input features to outputs, and they learn (i.e., train) using a back-fed system, producing a set of weights to calibrate the CNN (backpropagation, Figure 3).
Figure 3: Neural networks need to be trained to learn how to solve problems or challenges
The most computationally intensive process in machine learning is training neural networks. For a state-of-the-art network, this can take days to weeks, requiring billions of floating-point computations and large amounts of training data (GBytes to hundreds of GBytes) until the network achieves the desired accuracy. Fortunately, this step is not time-constrained in most cases and can be offloaded to the cloud.
Once the network is trained, it can be fed a new, unlabeled dataset and classify the data based on what it has learned previously. This step is called inference and is the practical goal of application development.
What Do You See?
Input classification can be performed in the cloud or at the edge (mostly offline). While processing data through neural networks typically requires dedicated accelerators (FPGAs, GPUs, DSPs, or ASICs), additional tasks are best handled by a CPU, which can be programmed with traditional programming languages. This is where FPGAs with integrated CPUs (so-called Systems-on-Chip (SoCs)) excel, especially at the edge. SoCs combine an inference accelerator (FPGA array) and a CPU on a single chip. The CPU runs control algorithms and manages data flow. At the same time, compared to GPU- or ASIC-based solutions, FPGAs offer numerous advantages, including easy integration of multiple interfaces and sensors, and flexibility to adapt to new neural network architectures (Figure 4).
Figure 4: Comparison of different technologies for AI inference applications
The inherent reconfigurability of FPGAs also allows them to leverage evolving neural network topologies, updated sensor types and configurations, and newer software algorithms. Using SoCs can guarantee low and deterministic latency when needed, for example, for real-time object detection. At the same time, SoCs are also very energy-efficient. The main challenge in achieving optimal performance from FPGAs is effectively mapping floating-point models to fixed-point FPGA implementations without losing accuracy (Figure 5), and this is where vendor tools come into play.
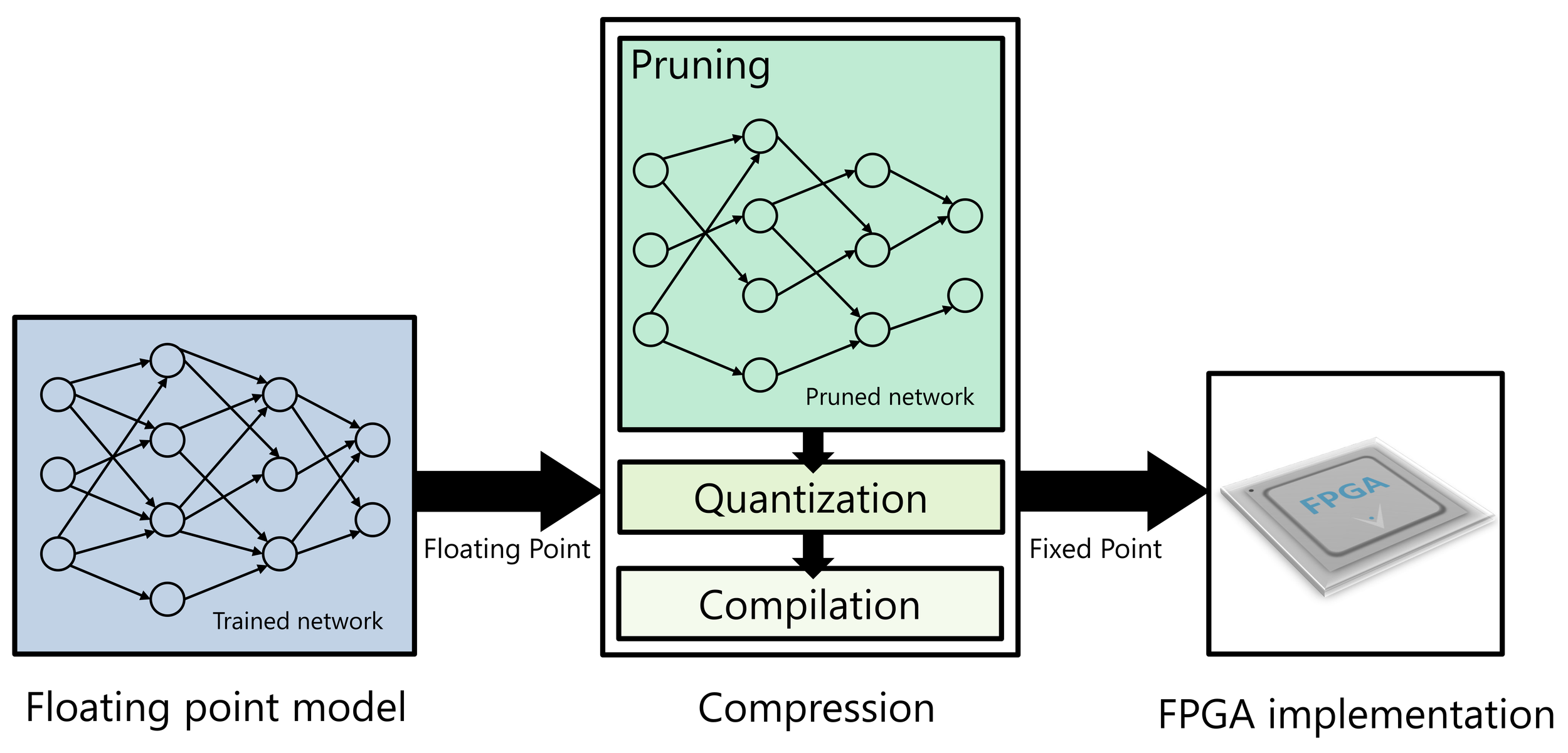
Figure 5: The process of effectively mapping floating-point models to fixed-point FPGA implementations is called quantization
Choosing the Right Tools
There are now many tools available to help lower the barrier to implementing a first AI project. For example, the Vitis AI Development Tools provide users with tools to develop and deploy machine learning applications for real-time inference on FPGAs. They support many common machine learning frameworks, such as Caffe and TensorFlow, with PyTorch support coming soon. They enable state-of-the-art neural networks to be efficiently adapted for FPGAs in embedded AI applications (Figure 5).

Figure 6: Core Board Module
Combined with standard System-on-Modules (SoMs), AI applications can be implemented faster than ever before (Figure 7).

Figure 7: Industry-proven AI application solution, based on Xilinx Zynq UltraScale+ MPSoC
To demonstrate the performance and rapid time-to-market capabilities of this combination, Xinmai Technology developed an AI-based image recognition system in just a few days. The images were captured using a standard USB camera connected to a Mars ST3 baseboard. For higher performance, the MIPI interface on the baseboard can be used.