Optimization and Implementation of a Zynq-based CNN Image Recognition Algorithm
Convolutional Neural Network Training and Hardware Accelerator Implementation The second part of the image recognition system is the CNN accelerator, whose implementation involves two stages: training and inference. The first is convolutional neural network training, which involves extracting the corresponding weight and bias values, i.e., the training stage. The second is implementing the convolutional neural network based on the network model and performing hardware acceleration to improve the speed of convolutional neural network operations, i.e., the inference stage. Convolutional Neural Network Training 4.1.1 Convolutional Neural Network Model Construction The Flowers Recognition dataset used in this paper consists of 4242 flower images, comprising 5 categories: daisy, tulip, rose, sunflower, and dandelion. Each category contains approximately 800 images, and each image has an approximate size of 320×240. However, the images are not scaled to a uniform size and have different aspect ratios. This paper adopts the VGG[9] network as the convolutional neural network model, which was proposed by the Visual Geometry Group at Oxford University in the 2014 ILSVRC competition. The VGG-11 network consists of 8 convolutional layers, 5 pooling layers, and 3 fully connected layers, taking 224×224×3 image data as input and outputting classification results for 1000 object categories. Given the characteristic distribution of the Flowers Recognition dataset, this paper keeps the network structure of the VGG-11 convolutional and pooling layers unchanged, adjusts the network structure of the fully connected layers, modifying the output channel counts of the last three fully connected layers to 1024, 128, and 5 respectively, resulting in the VGG-11 network structure shown in Figure 4.1.
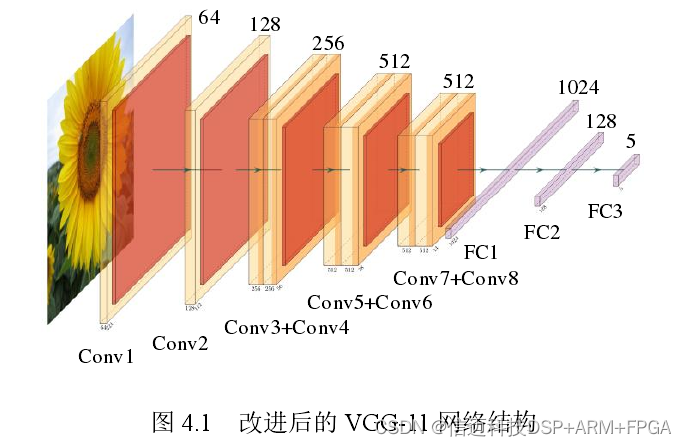
The convolutional neural network is built according to the network structure shown in Figure 4.1 and implemented using the PyTorch[17] neural network framework in this paper. The PyTorch neural network framework provides pre-trained VGG-11 network models on the ImageNet[57] dataset, and since the ImageNet dataset contains some flower images, transfer learning[58] is used to train the VGG-11 network.
4.1.2 Parameter Extraction
After the CNN network training is complete, the convolutional neural network model and its parameters are saved in a .pt file using the PyTorch neural network framework. While the PyTorch neural network framework provides a load method that can conveniently read parameters saved in a file, the output format is a tensor and cannot be used directly. Therefore, it is first converted to the Numpy [61] data format, then the parameters are extracted and saved in a fixed format, implemented according to the pseudocode shown in Algorithm 4.1.

For example, if the weight size of the last fully connected layer in the CNN network is 128×5, then the data saved by Numpy will be a 128-row, 5-column array. The values corresponding to shape(array)[0] and shape(array)[1] will be 128 and 5, respectively. array[i][j] corresponds to the element at row i and column j in the array, and a newline character is added after each element. The dimensions of bias values for all layers and weight values for convolutional layers differ from those of fully connected layers. Parameters can be extracted and saved using similar algorithms. The extracted data is saved to a .bin file. Then, the .bin file is copied to an SD card, and the corresponding weight and bias values are read from the SD card.