基于国产PCIE4.0/5.0 SWITCH 的AI服务器PCIe拓扑及12Gb SAS Expander多盘位背板应用研究(二)
2.2 拓扑特性分析
BalanceMode的配置将 GPU 平均挂接 在 2
个 CPU 下,GPU PCIe总的上行带宽较高;Com
monMode在一定程度上能够满足 GPU 之间点对
点的通信,同时可保障足够的 CPU 与 GPU 之间
的I/O 带宽;Cascade Mode只有一条 ×16 链路,
但由于 GPU 之间通过 PCIeSwitch串接,提升了
点对点的性能,降低了延迟。
对于双精度浮点运算,因 GPU 计算需要使用
处理器与主内存,由于 Dualroot的拓扑上行带宽
与内存使用率提升,其性能会优于 Singleroot的
拓扑。
对于深度学习推理性能来说,具备并行计算能
力的 GPU 可以基于训练过的网络进行数十亿次
的计算,从而快速识别出已知的模式或目标。不同
拓扑下 GPU 的互联关系不同,GPU 之间的沟通会
影响深度学习推理的整体性能。
3 实验及结果分析
3.1 实验装置
为探究在不同应用条件下3种拓扑的性能差
异,实验使用自研 AI服务器(NF5468M5)搭建机
台进行测试。装置使用2颗 CPU,规格为IntelⓇ
XeonⓇ Gold6142,主频为2.60GHz;使用12条
DDR4内存,容量为32GB,主频为2666 MHz;使
用8颗 GPU,规格为 NVIDIA Tesla-V100_32G。
3.2
实验结果分析
3.2.1
点对点带宽与延迟
对于 GPU 的 P2P性能,可以使用带宽与延迟
来衡量。PCIe3.0 的带宽为 16GB/s,理想状况
下,实际应用中带宽可以达到理论带宽的80%左
右。PCIe的延迟主要取决于 PCIeTrace的长度、
走线路径 上 的 器 件 及 是 否 经 过 UPI、是 否 跨 RC
(RootComplex)等。
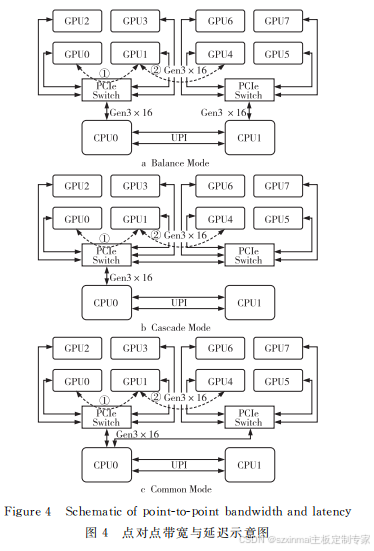
如图4所示,在 BalanceMode、CascadeMode
和 CommonMode3种拓扑中,分别测试挂在同一
个 PCIeSwitch下的 GPU (如图4中线路①)和跨
PCIeSwitch的 GPU(如图4中线路②)的点对点
带宽与延迟。测试结果如表1、表2及图5所示。
在同一个 PCIeSwitch下,由于 GPU 之间的
传输距离是一样的,所以在点对点回路①中,3种
拓扑的带宽与延迟结果皆相近;对于跨PCIeSwitc
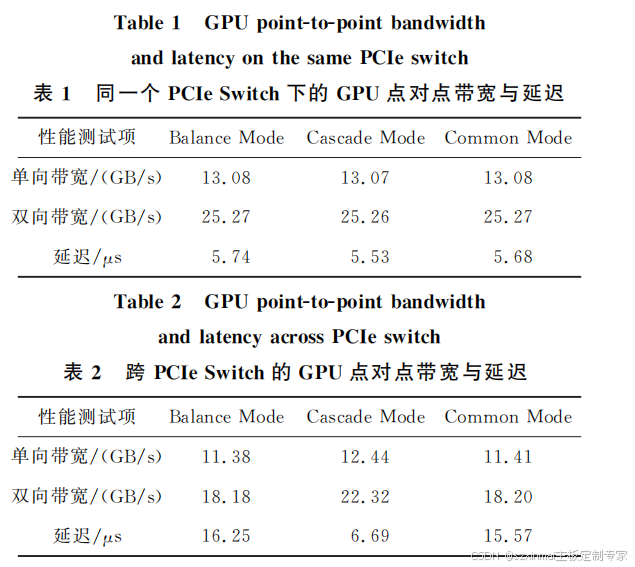
的2颗 GPU,由于 CPU 间为3UPILinks,其信号
传输速度足够快,所以 BalanceMode与 Common
Mode的 结 果 相 近,而 对 于 Cascade Mode,由 于
GPU 之间的沟通只需经过 PCIeSwitch,传输路径
变短,其点对点延迟性能得以提升;同时,对于In
telCPU 而言,一个PCIe×16Port为一个 RC,不
同 RC 之 间 的 通 信 带 宽 比 同 一 个 RC 下 PCIe
Switch之间的通信差,故 CascadeMode的带宽也
得以提升。
=========12Gb SAS Expander多盘位背板================
*硬盘热插拔功能;
*灯态支持硬盘上电,读写,报错;
*SPGIO硬盘报错功能;
*硬盘分时启动;
*风扇温度控制;
* I2C(BMC);

